
Verizy as a service is extremely simple to integrate into your product but, how it works behind-the-scenes is quite elaborate. Every document that Verizy processes undergo multiple layers of processing with various Machine Learning models and Computer Vision techniques.
Our engineers and researchers are constantly working on improving our algorithms to push our accuracies and overall performance further up.
Since we run a humongous amount of operations on each incoming document and our customers use Verizy during on-boarding of their customers, our infrastructure has to be resilient to down-times and spikes in traffic. Let me explain how we have achieved a 100% up-time in our 6 months of operation so far, with an overall 5.5M resource-intensive requests coming our way.
The Infrastructure
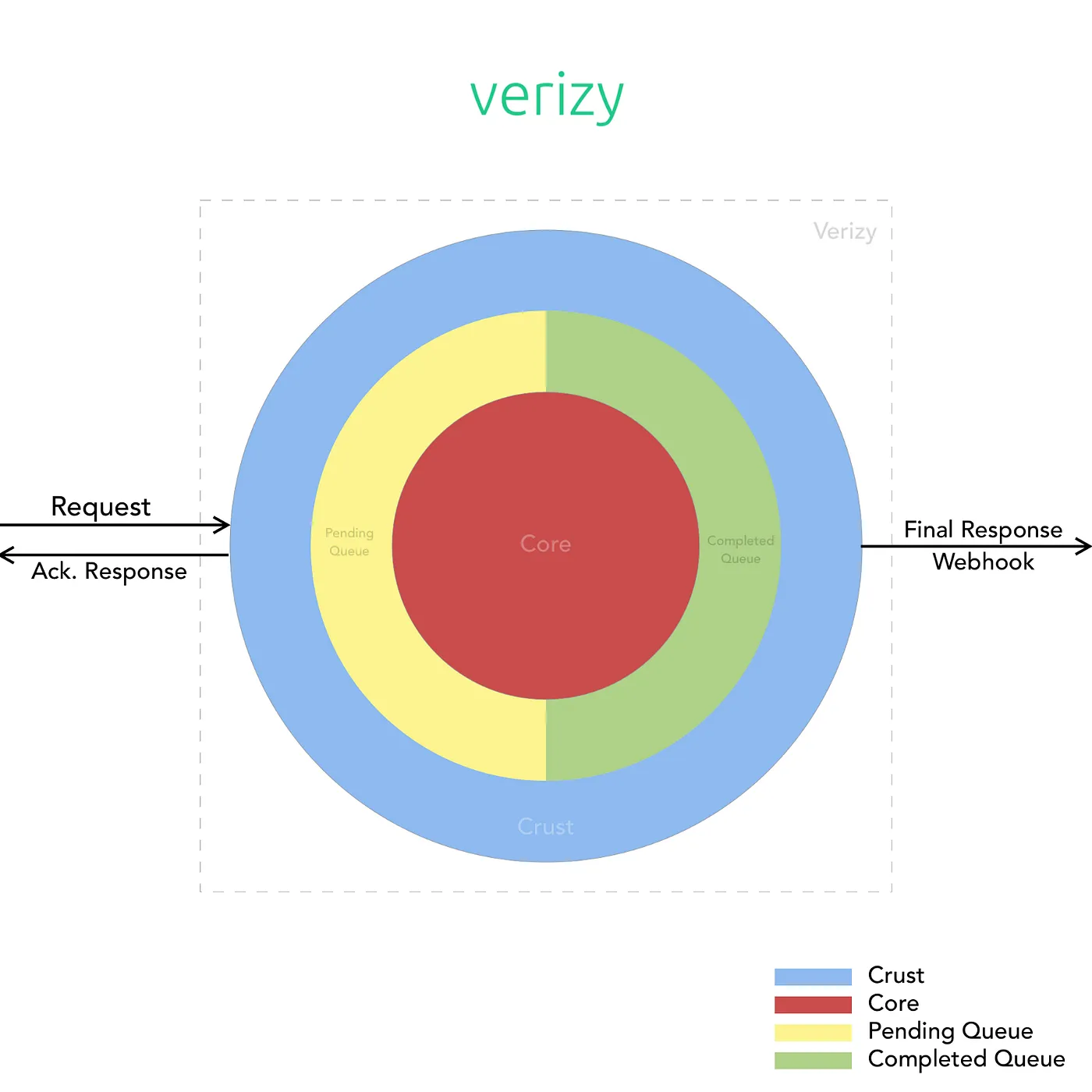
Our entire system is split into two main services called Crust and Core.

The Crust is what’s in touch with the incoming requests from the outside world, it’s basically an application that quickly authenticates requests, updates usage information, and queues the incoming tasks to the Core. The Crust and Core communicate using a FIFO queue. Each task queued for Core is assigned a unique identifier and logged on our database.
The Core is the brain of Verizy. All our ML models and vision algorithms exist in and are run on the Core. It is responsible for running the incoming requests through our array of models each designed for a certain purpose, running them through our custom OCR, and finally through our contextualization engine to make sense of all the extracted data.
The Core also handles any business logic validations that may be specifically requested by our customers.
The Crust and Core environments are both individually load-balanced and auto-scaled. They are set up so that they scale up or down based on the current number of tasks in the queue, the average CPU and RAM usage of the fleet of running instances, and certain other factors. We have also employed an ML-based pattern prediction algorithm that scales the fleet up or down preemptively depending on predicted traffic for a certain time of the day, day of the week, or day of the month.
Apart from this, we run our auto-scaled environments with a certain amount of redundancy that ensures that sudden loss of instances don’t affect our turn-around-time, and random spikes in traffic are immediately handled without needing a couple of minutes for the scaling-up to complete.
We deliver the processed results to the requests made by our customers over webhooks. This ensures an elegant and asynchronous format of communication between us and our customers.
Since we make constant updates to our Crust and Core systems, usually on a daily basis, we have streamlined our deployments in such a way that these constant changes to production do not affect the incoming traffic negatively. We always only conduct rolling deployments that add an additional batch of instances with the new versions of our applications and then replace the versions on the other instances in the same batch size, thus ensuring the same availability and load-capacity even during deployments, and never do we see downtimes due to maintenance. Before any new version is being deployed, we have a test suit that the new version is run on. Only on the successful completion of this does the new version gets deployed.
Summary
We have a light-weight, quick, and nimble Crust service that handles all requests from customers handles the delivery of webhooks to pass the processed responses and ensures all the incoming tasks are queued for Core to pick up. The Core service handles all the heavy-lifting and is the brain of our service.
By splitting our system into Crust and Core, we are able to independently scale the infrastructure needed to run each service. And, since the teams that work on each of these is also different, the segregation works out well even for our development workflow.
The queue we have in place ensures that no request is lost due to our system being overloaded.
With the combination of all these design and architectural decisions, we have been able to offer a 100% up-time of Verizy in the last 6 months.